Facebook ha una bellissima funzione che permette di scaricare su richiesta l'archivio dei tuoi dati personali.

Dal menu Impostazioni seleziona "Le tue informazioni su Facebook" e infine seleziona "Scarica le tue informazioni". Ora puoi richiedere un download.

Non è lo scopo di questo post elencare tutte le opzioni disponibili nella fase di creazione della copia di backup di Facebook; in sintesi è possibile filtrare la quantità di dati per periodo, categorie, qualità dei contenuti multimediali e per finire il formato. Due formati di presentazione dei dati sono disponibili: HTML e JSON.
Il formato JSON è il nostro caso di studio e a mio avviso il formato consigliato da scegliere per un'analisi più completa (basti pensare ai timestamp che nel formato JSON sono di valore numerico UTC mentre nell'HTML sono rappresentazioni localizzate di stringhe di difficile interpretazione).
Tuttavia se le stringhe contengono caratteri Unicode (es. le lettere accentate), i parser JSON non sono in grado di ricostruire le stringhe originali.
 |
| HTML |
 |
| JSON |
A prima vista sembra che Facebook rappresenti i caratteri in UTF-8 in modo non standard. Infatti, se prendiamo come riferimento il testo "può" nel formato HTML, il corrispondente testo in JSON è "può". Cosa c'è di sbagliato? Questa è la rappresentazione del testo in esame del file JSON in HxD Hex Editor:
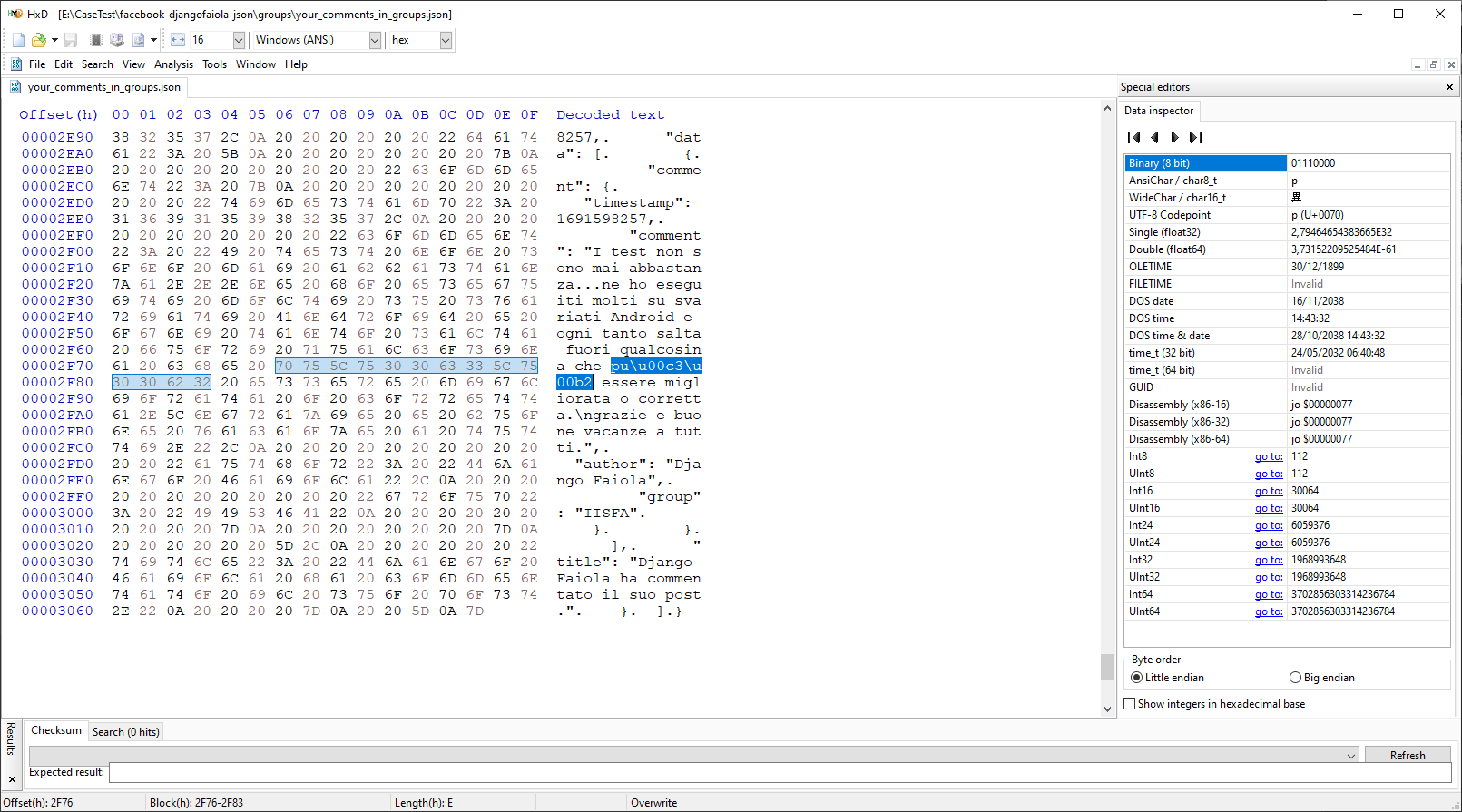
Il carattere "ò" è rappresentato dalla sequenza "\u00c3\u00b2" una coppia di caratteri Unicode che il parser interpreta come Latin-1 (che mappa esattamente i 256 caratteri ai 256 possibili valori di byte) "ò", invece dovrebbe essere un singolo carattere "\uc3b2". Questo significa che ogni carattere non ASCII è codificato due volte usando la sequenza di escape "\u00HH". Nel nostro caso il carattere "\uc3b2" è scritto come "\u00c3" (Ã) e "\u00b2" (²).
Soluzione
E' possibile correggere questa "anomalia" in due modi:
- Decodifica del JSON, codifica della stringa in Latin-1 e infine decodifica in UTF-8;
- Leggere il file come binario, individuare e sostituire tutte le doppie sequenze "\u00HH\u00HH" con l'unica sequenza "\uHHHH" e infine decodifica come JSON.
WhatsAppIZZA utilizza il metodo 2: usa una semplice regular expression per eseguire il match e poi la sostituzione dei valori.
(?i)\\u00([a-f0-9]{2})
Nel nostro caso "\u00c3\u00b2", dai match c3 e b2 ottiene "\uc3b2" che in UTF-8 è proprio il carattere "ò".



0 comments:
Posta un commento